预训练语言模型 - 融入知识图谱
1. ERNIE - 百度
百度的这篇文章更像是 Bert 模型对于中文的针对性改进,当然对英文也有一定的作用,但对于中文来说更明显。
1. 双向Transformer
ERNIE 同样采用多层的双向Transoformer 来作为特征提取的基本单元,这部分没啥创新,就是简单提一下。
2. 不同粒度的信息融合
ERNIE 同样采用了多种粒度信息,只不过不同粒度信息的预训练过程与 Bert 不同, 对于一个 token, 其同样由 token embedding + segment embedding + position embedding 组成,与 bert 相同, 每一句话的第一个 token 都为 [CLS]。
3. Basic-Level Masking 预训练
这个过程与 Bert 中的 MLM 类似,是对于词粒度的预训练。 对于英文而言,粒度为 word, 对于中文而言,粒度为字。
随机 Mask 输入序列中 15% 的 token, 然后预测这些被 mask 掉的 tokens。这点与 Bert 相同, 不同的是,其论文中没有提到十分采用类似 Bert 的那种 Mask 的Trick 来降低预训练与预测的不一致性,这点需要看代码确认一下。
4. Phrase-level Masking 预训练
我个人认为短语级别的粒度信息对于中文,英文来说都是有用的。
对于中文来说, 比如 “放你一马”, 这从单单的字粒度信息是学习不到的,且这种信息相当多。而对于英文来说,英文短语也不在少数,就像: pull up, pull down, push up, push down 我觉得word粒度对这种短语信息也是难以捕捉的。
在这部分的预训练过程中,首先采用对应的工具识别出句子中存在的 Phrase, 然后随机 Mask 句子中的一些短语(文章并没有说 mask 多少百分比), 然后预测 mask 掉的 Phrase 中的 word(字), 即以 word(字)为预测单元。
5. Entity-level Masking 预训练
实体信息包括人名,地名,组织名称,产品名称等, 而实体又是一种抽象的概念,且通常包含着一些重要的信息,且实体之间的关系也十分重要。 ERNIE 先用命名实体识别找出句子中的实体,然后与 Phrase-level 一样, mask 其中的一些实体并预测这些mask掉的 word (字)。
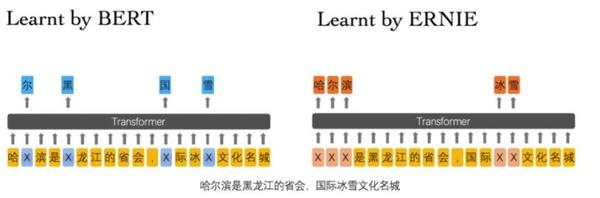
对此,Entity-level Masking 预训练能够捕捉到实体的语义信息,这点是毋庸置疑的,但对于实体间关系的抽取,从模型上来看并不突出,希望有大佬解释一下(论文中是提到可以学习到实体间关系,只是我对此存疑)。
6. 多源数据
ERNIE 在预训练时采用了多源数据,包括:中文维基百科,百度百科,百度新闻,百度贴吧。其中,百度贴吧由于其社区的特性,里面的内容是对话形式的,而 ERNIE 中对于 Segement Embedding 预训练与 Bert 的 NSP 不同的是,其采用 DLM 来获得这种句子粒度级别的信息,而这对于句子语义的把握更佳准确。
7. DLM:Dialogue Language Model
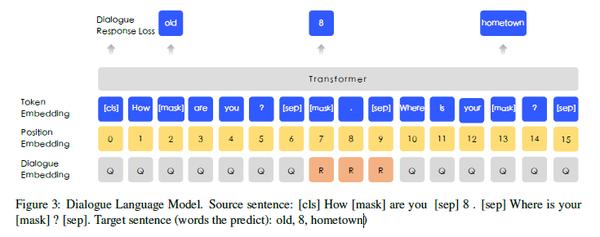
对比 Bert 中的 NSP, 似乎 DLM 更能把握句子的语义信息,且对于对话,问答这种形式的任务效果更好。 DLM 的训练过程与 NSP 也有很大的区别,其输入如下:
为了使得 ERNIE 能够表示多轮对话,其输入采用QRQ, QQR,QRR(Q表示Query, R表示Response) 这几种形式, 如上图就是 QRQ 的一个例子。 ERNIE 会 mask 掉输入的一些 token, 然后让模型去预测这些被 mask 掉的 token(文章并没有给出mask比例以及如何分配mask)。
同样有趣的是,ERNIE 也通过随机替换 Query 或 Response的方式来会添加一些 fake 样本来让模型去预测该输入是 real 还是 fake。
DLM 与 NSP 相比, 其更加复杂也更倾向于对话这种更高难度的任务,我个人认为,这种方式对于对话这种任务来说帮助很大。
ERNIE: 清华 [2]
清华的这篇文章与百度的有很大的差异,同样是引入外部知识,清华走了与百度完全不一样的道路,我们先来看看他们是怎么做的。
两篇文章对比,百度那篇文章更侧重于训练一个更好的预训练语言模型, 而清华的这篇文章更侧重于如何融入知识图谱。
融入知识图谱面临的两大挑战
知识图谱本质是 实体 + 实体间关系, 其中实体为点,实体间关系为边。而将知识图谱引入到预训练语言模型,有两个主要的挑战:
- Structed Knowledge Encoding: 对于给定的文本,如何有效的提取其中的知识图谱信息并对其进行 encode。
- Heterogeneous Information Fusion: 即如何将 encode 后的知识图谱信息融入预训练模型。
1. 模型架构
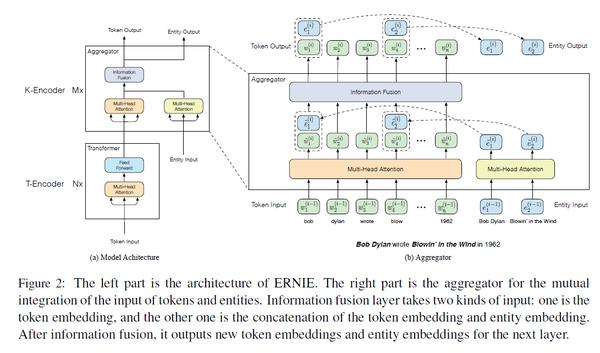
我们看到,上述整个模型可以整体分为两部分:
- T-Encoder: 与 Bert 的预训练过程完全相同,是一个多层的双向 Transformer encoder, 用来捕捉词汇和语法信息。
- K-Encoder: 本文创新点,描述如何将知识图谱融入到预训练模型。
2. 模型输入
对于一个给定的句子, 以下是其对应的 token 序列,划分按照word(字):
同时,文章采用命名实体识别的方式识别出句子中的实体,并与知识图谱中的实体进行对应, 由于实体往往不止一个token, 因此实体序列的长度与token序列的长度往往并不相等:
3. T - Encoder
前面提到,就是与 Bert 完全相同的,一个多层的双向 Transformer encoder, 其输出为:
4. TransE:encode 知识图谱
TransE 能够将实体与实体间关系转化为一种分布式表示, 而论文中就是采用这种方法,具体的我也不介绍了,对这方面了解有限:
5. K - Encoder
K - Encoder 的输入 tokens embedding 以及 entity embedding 首先分别经过一个多层的 Multi-head self-attentions(MH-ATTs):
然后要将 entity embedding 与 token embedding 融合, 其中,emtity 与 token 之间是有对应的,文中采用第一个 token 作为对应方式,一部分token有对应的entity, 一部分没有(如上图)。
对于有对应实体的情况,则有:
对于没有对应实体的情况,则有:
此处的激活函数可以选择 GELU, h_j 表示集成了 emtity 信息与 token 信息的隐层状态。
将上述操作简单描述, 那么第 i 个 aggregator 操作可以简述为:
6. dEA: denoising entity auto-encoder
从上式我们可以看出,该阶段的目的就是对于token序列与entity序列,计算每个token所对应的 entity 序列概率分布,以此来进行预训练。
该预训练模块的目的其实很明确,就是为了将 K-Encoder 输出的信息结合,毕竟不是每一个 token 都有对应的实体信息的。
在 dEA 的预训练过程中,考虑到 token 与 entity 之间的对齐误差, 因此采用一些策略进行调整:
- 5% 的情况下,对于给定的 token-entity 对,我们将实体替换为其他随机实体, 旨在减轻对齐过程所带来的误差。
- 15% 情况下,mask token-entity 对, 旨在减轻对于新 token-entity 所带来的误差
- 剩下80% , 保持不变。
7. 其余
论文中的细节与创新点就是这些,其余的我觉得看的意义不是很大,因此我就简单过了,感兴趣的可以看一看,毕竟咱也没有资源去试。
3. K-BERT
Reference
[1] ERNIE: Enhanced Representation through Knowledge Integration
[2] ERNIE: Enhanced Language Representation with Informative Entities