词向量与语言模型
1. 语言模型基础与词向量
语言模型可以简单理解为一个句子 s 在所有句子中出现的概率分布 P(s)。比如一个语料库中有100 个句子,『OK』这个句子出现了5次, 那么 $p(OK) = 5\%$。
那么,如何学习到这种概率分布呢? 最简单的方法是建立一个无比庞大的语料库,该语料库中包含了人类成百上千年间可能讲过的所有的话,那么我们不就可以算出这句话出现的概率了吗。可惜此方法不现实。
那么,能不能通过数学的方法进行表示呢?答案是可以滴,因为 S 是一个序列 $w_1, w_2 , \cdots ,w_n$,那么$p(s)$可以展开为:
那么现在的问题就变成了我们如何计算 $P(w_1, w_2, \cdots, w_n) $
统计方法 - n元模型
回忆概率论:
我们观察上式,会发现, $P(w1)$ 比较好算, $P(w_2|w_1) = \frac{w_1w_2}{w_1}$ 也还ok, $P(w_3|w_1,w_2)$ 就比较有难度了,随着n的增大,计算会越来越难, $P(w_n|w_1, w_2, \cdots, w{n-1})$ 几乎根本不可能估算出来。怎么办?
马尔可夫假设:假设任意一个词 $wi$ 出现的概率只同它前面的n个词 $(w{i-1}, \cdots, w_{i-n})$ 有关。由此,那么就有:
缺陷:
- 无法建模更远的关系,语料的不足使得无法训练更高阶的语言模型。
- 无法建模出词之间的相似度。
- 训练语料里面有些 n 元组没有出现过,其对应的条件概率就是 0,导致计算一整句话的概率为 0。解决这个问题有两种常用方法: 平滑法和回退法。
深度学习方法 - 神经网络语言模型[1]
首先,我们回到问题本身,我们为什么要计算 $p(s)$, 我们的目的是为了通过大规模语料库学习到语言内部的概率分布。那么有没有办法通过深度学习的方式来学习到这种概率分布呢?
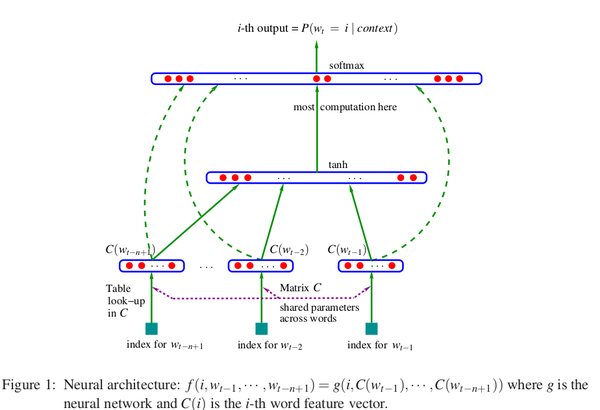
观察上图,假设有一组词序列: $w_1, w_2, \cdots, w_t$ ,其中 $w_i \in V$ , $V$ 是所有单词的集合。我们的输入是一个词序列,而我们的输出是一个概率值,表示根据context预测出下一个词是 $i$ 的概率。用数学来表示,我们最终是要训练一个模型:
- $wt $表示这个词序列中的第 $t$ 个单词, $w{t-n+1}$ 表示输入长度为n的词序列中的第一个单词
- $w_1^{t-1}$ 表示从第1个单词到第 $t-1$ 个单词组成的子序列
因此我们发现,该模型的每个样本其实计算的是:$p(wn|w_1, \cdots, w{n-1})$
词向量 - 表示语言的方式
前面我们通过 NNLM 可以知道,通过语言模型的训练,模型可以学习到语言的概率分布,那么如何将学习到的信息应用到下游任务呢? 这就是词向量产生的背景,如何用向量来表示语言信息,这里我们简单介绍下 Word2vec[4]。
首先明确一点的是, 词向量是语言模型的副产物。 怎么理解呢,意思是说,词向量是语言模型训练完成后产生的。
这里我们以word2vec 的 CBOW 训练模型为例:
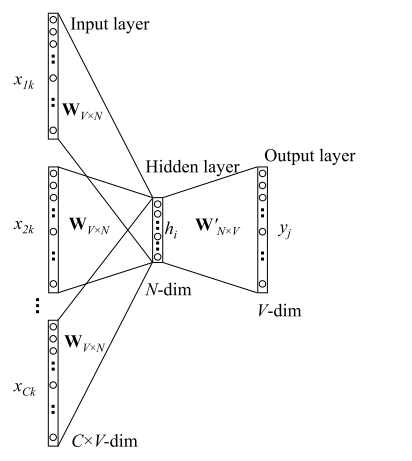
通过这样训练完成后,把 $W_{V\times N}$ 保存下来,我们就得到了词向量。
2. 预训练语言模型 - 用模型表示语言
前面提到,我们的最终目的还是通过语言模型来获得某种语言的表示,但是我们看到,上面那种训练方式,似乎不太合适,那个最后$W_{N\times V}$ 消失不见了,并且模型没有做深。
我们此处总结一下word2vec的弱点:
- 模型无法做深,词向量的表征能力有限,词向量的抽象程度不高
- 词向量获得的是上下文无关的,难以解决歧义问题上
- OV 词无法解决
很有意思的是, 相差几个月的时间, ELMO ,GPT, BERT 相继诞生了,都非常具有代表性。 下面会进行分别介绍。
0. NLP 特点
在进入预训练语言模型之前,我们先来看看对于NLP来说,最重要的是什么。
首先是 NLP 的特点:
输入是一个一维线性序列
输入是不定长的,这点对于模型处理起来会比较麻烦
单词位置与句子位置的相对位置很重要,互换可能导致完全不同的意思
句子中的长距离特征对于理解语义也非常关键。
其次是,NLP 中的几大常见的任务:
- 序列**标注:** 分词,词性标注,命名实体识别等。 特点是句子中每个单词要求模型根据上下文都要给出一个分类类别
- 分类任务: 文本分类, 情感分析。 特点是不管文章有多长,总体给出一个分类类别即可。
- 句子关系推断: QA, 自然语言推理。 特点是给定两个句子,模型判断出两个句子是否具备某种语义关系。
- 生成式任务:机器翻译, 文本摘要。特点是输入文本内容后,需要自主生成另外一段文字。
最后,我们来聊聊三大基本单元: CNN,LSTM,Transformer。
首先先看简单回顾下 Transformer的self-attention 机制,该机制在预训练语言模型中起到了至关重要的作用。我们看到,对于 Transformer 来说,通过self-attention 机制,词与词之间的关系一目了然,并且不会受到文本长度的限制。 然后注意,在 Attention is all you need 这篇文章中,Transformer 是 Encoder-decoder 架构的,这与后面BERT 所用的有所不同,后面BERT 所用的只是 transformer_block。
于是我们总结一下这三个基本单元的优缺点:
RNN:
- 优点:天生的具有时序结构,十分适合解决NLP问题
- 缺点:
- 反向传播时所存在的优化困难问题, 即梯度消失,梯度爆炸问题,进而导致对超长距离依赖的解决不佳
- 并行能力,进而导致难以做深
CNN:
- 优点:
- 可以并行,可以做的非常深
- 能够很好的捕捉 n-gram 特征
- 缺点:
- 无法解决长距离依赖问题
- 对于位置信息不敏感
Transformer:
- 优点:
- self-attention 天生的就解决了长距离依赖问题
- 可以并行,可以做的非常深
- 位置信息通过 position embedding 很好的补充了
- 缺点:
- 对于超长文本,会导致非常大的计算复杂度
- 位置信息依赖于 position embedding
1. ELMO
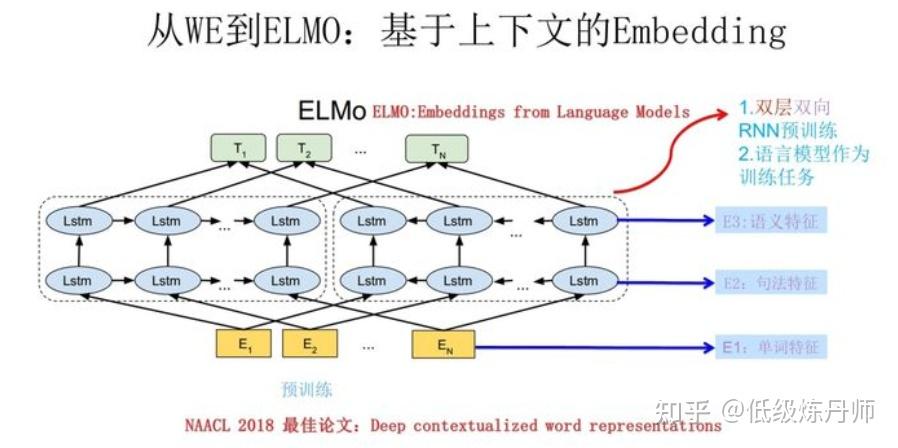
elmo 是通过 L 层的双向LSTM语言模型来学习上下文信息的,这就解决了上文提到的前两个问题,而针对 OV词, ELMO 采用了 char-level 来生成词向量进而进行训练。而对于ELMO 的不同层而言,不同层的 LSTM 能够把握不同粒度和层级的信息,比如浅层的 LSTM 把握的是单词特征, 中层的 LSTM 把握 句法 特征,深层的 LSTM 把握语义特征。
但, ELMO 的缺点也十分明显:
- LSTM 特征抽取能力远弱于 Transformer , 并行性差
- 拼接方式双向融合特征融合能力偏弱
- 层数浅,只有2层
2. BERT
语言模型:
我们先来看模型架构, BERT-base 采用12 层的 Transformer,这里简单提一下,BERT 的架构相当于 Transformer 的Encoder-decoder 架构中的Encoder。
再然后,我们看下,输入的组成部分,输入包含三个部分,分别是
- token embedding:词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings:区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings:和之前文章中的Transformer不一样,不是三角函数而是学习出来的
最后,我们看下预训练训练任务部分。
首先是 Masked LM:随机遮蔽输入 token 的15%,然后预测被遮住的 token。这样会带来一个问题,即训练与微调阶段的不一致性,因为训练阶段采用了 [MASK] 而 fine-tune 阶段并没有。为了减轻该问题, we do not always replace “masked” words with the actual [MASK] token. 具体做法如下:
假如我们有一句话, my dog is hairy , 被选中的词为hairy,数据生成器并不总是将hairy替换为[MASK],此时的过程如下:
- 80% 情况下: 用[MASK] 替换 hairy
- 10% 情况下: 随机选一个词如apple 来替换hairy
- 10%: 不改变这句话
然后是 NSP,即Next Sentence Prediction,选定一个句子A,B作为预训练样本,B有50%的可能是A的下一句,也有50%的可能是语料库的随机句子。
2. GPT 1.0
其实GPT 1.0 要比 BERT 出来的早,但是吃了不会宣传的亏啊。首先来看语言模型:
跟bert 有很明显的差别,但是符合原来语言模型的的定义。
其次, 模型结构采用单向Transformer, 这是由于语言模型决定的。
第三个是, embedding 不包含 NSP 这种 segment embedding。
说到这里,我们就说完了基础的三个预训练语言模型,接下来我们探讨下如何更好的使用预训练语言模型。
3. 如何使用预训练语言模型
1. 是否要进行微调[1]
我们是直接采用训练好的向量还是用预训练语言模型进行微调呢?
『冰』表示freeze, 『火』表示微调的结果。
实际上,对于大多数的任务, BERT 进行微调的方式总是比提取向量再训练的方式能够获得更佳的效果。因此,在条件允许的情况下,推荐采用微调的方式。
2. 是否要进行再次预训练[2]
答案是需要。
我们知道现在的预训练语料采用的都是百科,书籍等比较规范的数据,而实际业务中的数据千差万别,可以这么理解,预训练本身获得的是语料库中文本的分布,而如果预训练数据分布与业务数据分布偏差较大,会带来一些负面影响。
因此,针对一些业务,如果数据与百科数据差别非常大,先进行预训练,然后再进行微调是一种比较合适的方式。
我们这里简单介绍下[2] 中的结论
- 在目标领域的数据集上继续预训练(DAPT)可以提升效果;目标领域与语言模型的原始预训练语料越不相关,DAPT效果则提升更明显。
- 在具体任务的数据集上继续预训练(TAPT)可以十分“廉价”地提升效果。
- 结合二者(先进行DAPT,再进行TAPT)可以进一步提升效果。
- 如果能获取更多的、任务相关的无标注数据继续预训练(Curated-TAPT),效果则最佳。
3. BERT 向量 vs Glove 向量
接下来我们分析下 , BERT 相对于 Glove 向量,到底强在哪里。 首先是训练数据规模的影响,
- 随着数据规模的扩大,Glove 向量的表现与 BERT 向量的表现差距越来越小,我们看到当训练数据足够多的时候,Glove 在一些任务上能够获得略差于BERT的影响,但是在绝大多数情况下依旧比BERT 向量差很多,这说明 BERT 对于小数据集的优越性。
- 在简单任务上,随着数据量的增加, Glove 能达到 BERT 十分接近的效果
然后是语言特征:
- the complexity of text structure:句子结构的复杂性
- Ambiguity in word usage: 单词的歧义性。
- Prevalence of unseen words:未登录词出现的概率
上图我们可以得出以 BERT 为代表的 Contextual embeddings 在解决一些文本结构复杂度高和单词歧义性方面有显著的效果。
4. 预训练语言模型 - 后时代

首先,我们来分析一下这张图,从上往下:
- Contextual: 谈论 静态 embedding 与 上下文 embedding,被做烂了,pass。
- Architectures: 模型整体架构,这部分还有的探讨,可以参见上面 T5 的Model Architecture 部分。 目前业界还没有统一的标准说应该选择哪种架构,不过从 T5 的效果来看, Transformer+Encoder+Decoder 的效果是最好的,但参数量也上去了。其实就目前来看,研究的意义不是很大了,除非说能出现一个大的突破。
- Task Types: 谈论了两件事: 语言模型的选择以及Contrastive Learning,其实这两个应该分开讨论。
- Multi-Lingual: 从多国语言的角度出发,这方面不太懂,也不感兴趣,觉得用处不会太大。
- Multi-Modal: 多模角度,我个人认为这对于工业界是十分有意义的。
- Knowledge Enriched: 知识 + 预训练语言模型,我觉得这是一个很值得研究的方向,无论是在工业界和学术界。
- Domain Specific: 特定领域 + 预训练语言模型,我觉得这方面很有搞头,毕竟很多专有领域跟公共领域还是很不同的,比如医学,生物,法学等。由于每看过相关文章,无法说上面的模型与 bert在同样语料上预训练后哪个效果好,但还是有一定参考价值的。
- Language-Specific: 这块我觉得还是很有研究价值的,毕竟我们中文跟英文从各个方面来说差距还是蛮大的,如果能对语言有深入了解,感觉还有搞头。
- Model Compression: 模型压缩,这个在工业界用处很大,十分建议研究,需求也很大,一些蒸馏方法所需要的资源门槛也比较低,如果有资源,有idea,建议入坑。
考虑到涉及到的内容太多,我这里抽取四个部分讨论,分别是: Architectures, Task Types, Knowledge Enriched 以及 language generation。
1. AE vs AR
AR 语言模型:自回归语言模型,指的是,依据前面(或后面)出现的 tokens 来预测当前时刻的 token, 代表有 ELMO, GPT 等。
AE 语言模型:通过上下文信息来预测被 mask 的 token, 代表有 BERT , Word2Vec(CBOW) 。
AR 语言模型:
- 缺点:它只能利用单向语义而不能同时利用上下文信息。 ELMO 通过双向都做AR 模型,然后进行拼接,但从结果来看,效果并不是太好。
- 优点: 对生成模型友好,天然符合生成式任务的生成过程。这也是为什么 GPT 能够编故事的原因。
AE 语言模型:
- 缺点: 由于训练中采用了 [MASK] 标记,导致预训练与微调阶段不一致的问题。 此外对于生成式问题, AE 模型也显得捉襟见肘,这也是目前 BERT 为数不多实现大的突破的领域。
- 优点: 能够很好的编码上下文语义信息, 在自然语言理解相关的下游任务上表现突出。
2. GPT 系列
1. GPT 2.0
GPT 2.0 验证了数据的重要性,即使单纯的从数据角度入手,效果就可以获得巨大的提升。GPT 2.0 采用800w 互联网网页数据,这样训练出来的语言模型,能够覆盖几乎所有领域的内容。
第二个意义在于,GPT 2.0 开始探索了预训练语言模型在 zero-shot 下的表现。这方面在GPT 3.0 中体现的淋漓尽致。
- 预训练数据与网络深度的重要性,目前也没有到极限。
- GPT 2.0 的生成效果非常惊艳,至少语法,流畅度等方面是没有问题的,就是没有灵魂
- zero-flot 也不是不可以
2.0 GPT 3.0
先来介绍一下几个概念:
- FT,fine-tuning:就是微调啦
- FS,few-shot:允许输入数条范例和一则任务说明
- One-shot:只允许输入一条范例和一则任务说明
- Zero-shot:不允许输入任何范例,只允许输入一则任务说明
GPT 3.0 本质上是探索超大型预训练语言模型在 few-shot,one-shot,zero-shot 上的可能性,这是延续之前 GPT 2.0 的研究,整体上,GPT 3.0 在 zero-shot 下能获得相当不错的结果。
3. BERT 系列
1. Roberta
roberta 是bert 的一个完善版,相对于模型架构之类的都没有改变,改变的只是三个方面:
- 预训练数据:
- BERT采用了BOOKCORPUS 和英文维基百科, 总共16GB。而 RoBERTa采用了BOOKCORPUS + 英文维基百科+ CC-NEWS+OPENWEBTEXT+STORIES, 总共160GB。
- Roberta 于bert 都采用 512 个token 作为序列长度,但与bert不同的是, robert 不会随机掺杂一些短句,这意味着 roberta 采用的都是长句。
动态mask vs 静态 mask:
- 静态mask:Bert 在准备训练数据时,每个样本只会进行一次随机mask,每个epoch都重复使用,后续的每个训练步都采用相同的mask。
- 修改版静态mask: 在预处理时将数据集拷贝10次,每份数据采用不同的mask。
- 动态mask:不在预处理时进行mask,而是在每次向模型输入时动态生成mask
数据格式与NSP:
- Segment-pair + NSP:与bert一样。输入包含两个 segment,这两个segment可能会来自同一个文档或不同文档,两个segment 的token 数均小于 512,预训练任务包含 MLM 与 NSP。
- Sentence+pair + NSP:输入包含两个 sentence,两个句子可能来自同一文档或不同文档,两个句子 token 数均少于 512。预训练任务包含 MLM 与 NSP。
- Full-sentences:输入只有一部分,来自同一个文档或不同文档的连续句子,token总数不超过512。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界token。不包含NSP任务。
- Doc-sentences:输入只有一部分,输入来自同一个文档的连续句子,token总数不超过512。预训练不包含 NSP 任务。
通过四个对比实验我们发现:
- Segment-pair 较好于 sentence-pair,可能是因为 segment 能够学习到长距离依赖关系。
- Doc-sentences 几乎在所有任务中表现最佳,这意味着 NSP 任务没有什么用
- Doc-sentences 略好于 Full-sentences。
2. T5
4. 预训练语言模型与自然语言生成
这里我们先来回顾一下BERT和GPT, 前面提到, BERT 本质上相当于 Transformer 中的 Encoder, 而GPT 相当于 Transformer 中的 Decoder。既然我们已经验证了 Transformer 在文本生成领域的成功,尤其是机器翻译领域, 那么当我们想用于生成问题的时候,很自然的想到有没有办法把二者结合起来呢?
MASS 就是基于这样的思想。
1. MASS
MASS 的思想很简单, 对于输入序列 x, mask 该句从 u 到 v 位置上的token,记为 $x^{\u:v}$, 而对应的, 从 u 到 v 位置上的 token 片段记为 $x^{u:v}$ 。 k = v - u + 1 表示 mask 的窗口大小 , 表示一句话中多少个 token 被 mask 。 对于 MASS 的语言模型来说, 其输入为 mask 后的序列 $x^{\u:v}$ , 输出为被 mask 后的序列 $x^{u:v}$。
为何 MASS 适合生成
首先, 通过 Seq2Seq 框架来预测被 mask 的tokens 使得 Encoder 去学习没有被 mask 的 token 的信息, 而Decoder 去学习如何从 Encoder 中提取有效的信息。
然后, 与预测离散的 tokens相比,Decoder 通过预测连续的 tokens, 其能够建立很好的语言生成能力。
最后, 通过输入与输出的 mask 匹配, 使得 Decoder 能够从Encoder 中提取到有意义的信息,而不是利用之前的信息。
MASS 总结来说有以下几点重新:
- 引入了 Seq2Seq 来训练预训练模型。
- mask 掉的是一段连续的tokens而不是离散的 mask, 有助于模型生成语言的能力。
- Encoder 中是 mask 掉的序列,而 Decoder 中是对应被mask的 tokens。
2. UNILM
UNILM 同样想融合bert与gpt ,然而走了与 MASS 完全不同的路子,它想通过多任务学习的方式来解决。UNILM 这篇文章,厉害在同时使用多个预训练语言模型训练这个思想,在预训练任务中包含了三种语言模型:
Bidirectional LM : BERT 的 mask LM
Unidirectional LM:GPT 的 语言模型,包括 left-to-right 到 right-to-left
Seq2Seq LM: 句子间LM。输入两个句子,第一个句子采用双向LM方式,第二个采用单向LM 方式。
3. BART
BART 与 MASS 的基本思想一致,都是受到 Transformer 在机器翻译领域的成功,尝试将 Transformer架构跟预训练结合起来。
但是与 MASS 不同的是,他们输入的数据格式有很大的差别,Decoder 也有较大的差别。与MASS 相比, BART 完全延续 Transformer 原来的架构方式。
训练数据:
- Token Masking 和BERT一样,随机选择token用[MASK] 代替。
- Token Deletion 随机删除token,模型必须确定哪些位置缺少输入。
- Text Filling 屏蔽一个文段,文段长度服从泊松分布(λ=3)。每个文段被一个[MASK]标记替换。如果文段长度为0,意味插入一个[MASK]标记(灵感来自Span-BERT)。
- Sentence Permutation 以句号作为分割符,将一篇文章分成多个句子,并随机打乱。
- Document Rotation 随机均匀地选择一个token,以这个token为中心,旋转文档,选中的这个token作为新的开头,此任务训练模型以识别文档的开头。
5. 预训练语言模型融入知识
1. ERNIE
ERINE 的网络架构,语言模型等与 BERT 完全相同,与BERT 不同的主要有两点:
- 数据的mask
- NSP 任务 与 DLM
首先我们来看 mask 方式,ERNIE 的 mask 包括三部分:
BERT 的 basic-level mask 预训练
Phrase-level 预训练
Entity-level 预训练
但是我们反过来看这篇文章,它融入知识了吗? 我觉得没有,对于知识图谱来说,实体本身的含义很重要,但是实体的关系同样非常重要,而这篇文章并没有融入任何的关系信息。
2. ERNIE (清华)
这篇文章最核心的点在于,将BERT的信息与TransE 的信息进行融合
我们看到,上述整个模型可以整体分为两部分:
- T-Encoder: 与 Bert 的预训练过程完全相同,是一个多层的双向 Transformer encoder, 用来捕捉词汇和语法信息。
- K-Encoder: 本文创新点,描述如何将知识图谱融入到预训练模型。
3. K-BERT
Reference
语言模型基础与词向量:
[1] A Neural Probabilistic Language Model
[2] Mikolov, T.(2013). Distributed Representations of Words and Phrases and their Compositionality.
[3] Mikolov, T.(2013). Efficient Estimation of Word Representations in Vector Space.
[4] Rong, X. (2014). word2vec Parameter Learning Explained.
预训练语言模型:
[1] ELMO: Deep contextualized word representations
[2] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[3] GPT 1.0: Improving Language Understanding by Generative Pre-Training
[4] GPT 2.0: Language Models are Unsupervised Multitask Learners
[5] GPT 3.0: Language Models are Few-Shot Learners
应用预训练语言模型:
[1] To tune or not to tune? adapting pretrained representations to diverse tasks.
[2] Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks
预训练语言模型 - 后时代:
[2] ERNIE - Enhanced Language Representation with Informative Entities
[3] ERNIE - Enhanced Representation through Knowledge Integration
[4] ERNIE 2.0 - A Continual Pre-training Framework for Language Understanding
[5] MASS - Masked Sequence to Sequence Pre-training for Language Generation
[6] UNILM - Unified Language Model Pre-training for Natural Language Understanding and Generation
[7] XLNet - Generalized Autoregressive Pretraining for Language Understanding
[8] RoBERTa - A Robustly Optimized BERT Pretraining Approach
[9] TransformerXL: Attentive Language Models Beyond a Fixed-Length Context
如何预训练一个好的预训练语言模型:
[1] Pre-trained Models for Natural Language Processing: A Survey
[2] T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
1 | Bag of Tricks for Efficient Text Classification |